The elementary work on the dm4-wikidata-toolkit module now done allows for easy adaptation and variation. Variation and revision are actually two of many good reasons for posting about this early and releasing stuff. This gives me the time to hold back for a moment, re-focus and reflect on what has been done and learnt. After this infokitchen-dinner i would to think and talk with you about: What if many different parties would do expose varying aspects of the full and public wikidata as a service (API)? What data covering which aspects of the world is in wikidata and which do we want to cultivate there? And ultimately, does this look like a good approach to be investigated any deeper?

Technical background
The dm4-wikidata-toolkit module got started as a branch of the wikidata search mode for deepamehta4 when i started to work with the so called “wikidata dumps” (=one-point-in-time, complete database exports) instead of performing GET requests against the HTTP API endpoint of wikidata.org. Now after that switch of methods in last December i decided to spin that branch off into a dedicated plugin which solely builds on top of the work done by Markus Kroetzsch (and others) who developed the WikidataToolkit. So this plugin integrates the WDTK into the OSGi environment of Deepamehta 4. For developers it maybe noteworthy that DeepaMehta 4 uses Neo4J as its current storage layer and it allows for integration of other Neo4J modules. Thus our storage layer has already built-in basic support for spatial and time ranges queries over the transformed data. Once the data is within deepamehta4, we can very easily write custom queries (through JAX-RS) and expose a REST API query endpoint, if we know a bit of Java and know how to traverse a graph.
In the example live here i focused on analyzing and exposing certain aspects of wikidata to answer the question (among others): Who was employed by the BBC while being a citizen of Germany? The custom endpoint at http://wikidata-topics.beta.wmflabs.org/wdtk/list/ is able to serve JSON topics and inform your application about Cities, Countries, Persons and Institutions stored, described and related to each other in wikidata. Adapting this and writing another custom endpoint is, with dm4-wikidata-toolkit, a pretty straight forward job. The complete transformation (analyze, import and mapping) process is outlined at the end of this post. The implementation and documentation for the four, currently supported custom queries can be found here from line 160 onwards.
Usage scenarios and research on use-cases
When surfing around the topic of “wikidata query service” i found a few pages proposing “user stories” and these examples (from my experience) prove always very insightful for developers trying to meet some needs. As described by Phase 3 of the wikidata project, which is the current stage, the latest and widest goal is the deployment and roll-out of listings on wikipedia pages . The advantage of this for Wikipedians seems to be that these future list are not going to be manually edited and maintained in n-hundred versions anymore but just at one place which then gets integrated into all (language specific) Wikipedia pages. To further inform yourself about some questions which a wikidata query endpoint should be able to answer you might want to jump on reading this page.
In plain terms, for the respectively transformed wikidata, our endpoint can currently answer simple queries (all items using a certain property, all items using a certain property involving a specific item) and a query “walking along” two properties (employee of, citizen of) involving two specific items (BBC, Germany) – called a traversing with? query. A special feature of our approach is that we can also respond with a list of all claims for a given wikidata propertyId while naming both involved players (items) for the respective claim. One disadvantage for the latter (“claim listing query”) is that the result set will definitely be very large and that we (currently) can not skim or page through it.
After searching a bit more i came across the following page created as a research documentation by the developers (Wikibase Indexing) and was a bit struck by how much of its content i could relate to. It was that page where i heard about WikiGrok for the first time, a few weeks ago. There it is written that a query-service could be valuable in detecting and thus filling up niche-areas in wikidata through engaging mobile users with a mobile frontend/web-app called WikiGrok.
After having connected the dots from the contents of these wiki pages, with the super-next release of this plugin i might very well aim at the goals set by this page. Read on to get to know more about what this effort covers.
General purpose vs. focusing on usage scenarios
Building a general purpose query engine seems like quite a tough job to do (i can imagine). And not that i am so hard lazy but focusing on offering a query-endpoint covering just a specific part of the whole wikidata dataset sounds like a reasonably good idea, too. Especially the subject of optimization, as well as engaging a specific target audience for further collaborative editing, improvement and therewith community driven “quality control” may be more in the reach (and may be of benefit for wikidata as a whole) when just covering certain facets of wikidata. Thinking of small, independently deploy-able units all contributing to a bigger goal isn’t that one of the ideas behind a micro-service architecture? I must think so.
If you are not so much interested in how the transformation process works i recommend you to process with the super-next paragraph and start thinking of your field of interest while reading it.
How the import process works
The current version of this plug-in focuses on matching four types available in the DeepaMehta4 Standard Distribution onto wikidata items, namely: Persons, Institutions, Cities and Countries. By default labels and alias are imported but descriptions and related URLs can be imported as well using the configuration. The user can control the language of values to be imported and set a timeout for how long the importer process should run over the dump. All this is interactively do’able after installing deepamehta 4.5 (with Java 7), dropping the dm4-wikidata-toolkit release into your /bundles folder and using the “Wikidata Dump Import” topic commands (reveal it via a “By Type” search). The only thing what remains to be configured is to associate (map) the imported Wikidata Property items to the corresponding Association Types.
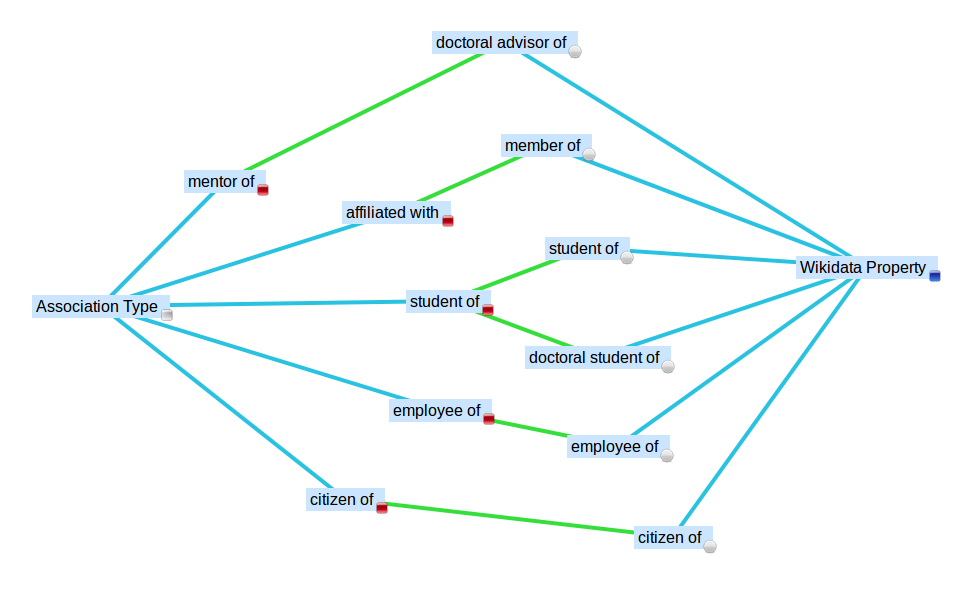
A lot of questions remain but the first questions are answered. In the foreword i asked: Which “citizen of” the country “Germany” “currently works” or “has worked” for the “British Broadcasting Corporation”? With having this, developers can either get the answer from here or from their own after installing and setting up their own wikidata endpoint.
The import process processes a wikidata json dumpfile (optionally also downloads one) and can be run many times on the same database because before creation all entities and claims get matched by UID so no elements are duplicated. Please consider that running the importer process for more than 2secs will take time, space on your hard-disk (starting at 5-8 GB), quite a bit of computing power (multi core i-5) and at least 4 GByte RAM.
The current implementation of the “entity processor” requires, for creating statements/claims between two items, that both items involved in the claim already exist in your database which means: All the claims relating two items are just created in your database when you run the import process for the second time.
- Search, browse and navigate entities on wikidata.org (analyse the interesting aspects of wikidata for your use-case through identifying items and properties and noting their technical IDs)
- Map all items for your use case to (existing or new) Topic Types and map properties onto (existing or new) Association Types provided by your dm4-storage layer (see diagram above)
- Adapt and compile the modules code responsible to select the aspect of wikidata and transform them into instance of your types (see WikidataEntityProcessor.java)
- Trigger the “Create topics” command of your “Wikidata Dump Import” configuration topic available via the standard dm4-webclient
Deletion is not yet implemented, so if items are deleted in the dump they are not deleted in your deepamehta4 database.
Attention, please note: As of 24 November 2015 this service is not in operation anymore.
To get started with adjusting the code to your needs please follow this PluginDevelopmentGuide and use the plugins source code repository at https://github.com/mukil/dm4-wikidata-toolkit
Analysis and identification of your sub-domain in wikidata
Looking at the summary table of available properties, our import matches kind of a random mix and minimal subset of properties from the vocabulary for “Organization” and “Person”. And on a second look at this incomplete and interesting summary table, each section of the page might be worth mapping onto deepamehta4 types and thus turning it into another coherent RESTful query endpoint. For example just the vocabulary around “Works” connects various library identifiers and each one of the various “Terminologies” covers a field of work on its own (Medicine, Chemistry, Biology or Mineralogy). Also the section on “Geographical features” has become quite a rich vocabulary for describing the physical aspects of our planet earth in a database. Specialized query endpoints, this might be what Denny V. and others had in mind when writing up his thoughts about a categorical imperative in wikidata.
All of these vocabularies have in common that they are developed (openly) and managed by a community of people (just found this page to organize in such) which try to take care of building a quality vocabulary and data. They discuss and introduce terms which they think are useful in describing our outer, “real world” and the relationships people, materials, services have to it. These properties are nothing less then the core building blocks of the current and future knowledge to be formulated in wikidata.
The froods case
One colorful example is, with some people at digitalmemex.com i was talking about building one of our topic map showcases around one of wikidata’s core features: It is a multilingual semantic network that potentially anyone can edit! So our aim would be to engage us with others over a custom UI and try to author a multilingual cookbook through re-using and mixing Ingredients (latin name, name, description) which we find and edit on wikidata only. We have already analyzed some of the relevant terms and items in wikidata (like Pea) already can be described as “instances of” fruit (Q3314483), herb (Q207123), nut (Q11009), edible fungi (Q654236) and vegetable (Q11004). We could now ask you and our friends to start using these. The only technical thing to implement in our code is to also import labels and descriptions of other available languages into and then provide a “language selector” in our showcase cookbook.
Having a truly multilingual cookbook at hand would be quite a thing, no? Bridging kitchen cultures with an app, i mean, have you recently heard about anything aiming this high? Until we’ report on this getting started here, let us continue to meet (or try to meet more often) in our counterparts kitchen.
Cracking some of the teasers (“hard nuts”)
At foremost, dates and times remain an issue to solve (as all qualifier snaks). My next playground will be importing and indexing geo-coordinates for this endpoint, as everything is already setup for it, we just need to store the values and write one new method. Also not selecting and transforming the data before import would allow to have more “raw” wikidata insights, a general importer might be do’able from here on
Another open challenge will be, how would one manage and operate this endpoint on the most up-to-date wikidata. If one wants to support the case of WikiGrok the importer should analyze and then focus on data which can engage users in filling up gaps in wikidata, helping users to transform unstructured wikipedia contents into wikidata.
If you want to join the development or at least, play with and setup your development environment, please follow use this PluginDevelopmentGuide to get started and use the plugins source code repository at https://github.com/mukil/dm4-wikidata-toolkit
Please have a look at the REST API help. Also, if you’re interested how simple introducing new custom query endpoints has been for me as an application developer, take a short look on github.com into the java implementation of the four currently available queries.
I am looking forward to talk about answering some of the more harder questions with you. Thank you very much for reading and have a nice day!
Please note:
At the 21st of April 2015 me and some others of deepamehta4/digitalmemex will be at the Wikimedia e.V., Headquarter Berlin and i will be very happy to join forces and discuss with you about all this from 6 to 7pm.